
Hello world à tous !
Il y a deux ans, en 2016, j’avais fait un petit interpréteur d’algorithme en C# pour m’amuser. Ca fonctionnait plutôt bien mais ça ressemblait plus à un PoC qu’autre chose.
Plus récemment, j’ai repris ce projet pour en faire quelque chose de plus complet et de plus propre. Le but est toujours de m’amuser et d’apprendre. Le but n’est pas de proposer une nouvelle technologie ou de rivaliser quoi que ce soit.
BaZic
Bref, prenons un langage simple, au hasard, le Basic, faisons-le à notre sauce, mettons un « Z » au milieu du nom (comme dans tous mes projets, je ne vous apprend rien), et PAF, voici BaZic !
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
FUNCTION Main(args[]) VARIABLE result = Fibonacci(9) System.Console.WriteLine("Fib 9 = " + result) RETURN result END FUNCTION FUNCTION Fibonacci(n) # To return the first Fibonacci number IF n = 0 THEN RETURN 0 END IF VARIABLE a = 0 VARIABLE b = 1 VARIABLE c = 0 VARIABLE i = 2 DO WHILE i <= n c = a + b a = b b = c i = i + 1 LOOP RETURN b END FUNCTION |
BaZic est un langage procédural semi-dynamique orienté objet avec une syntaxe simple permettant d’exécuter des petits programmes pouvant en partie exploiter les APIs .Net.
L’exemple de code ci-dessous ne fait absolument rien de concret. Il est là pour montrer la plupart des possibilités syntaxiques en un seul bloque de code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# BaZically, this program does nothing interesting... VARIABLE myVar[] = NEW ["value1", "val2"] FUNCTION Main(args[]) MyFunction(1, 2, NULL) END FUNCTION FUNCTION MyFunction(arg1, arg2, arg3[]) DO VARIABLE x = 1 + 2 * (3 + 4 + 5) x = myVar[0] x = "This is a string on several lines with spaces and tabs" + x.ToString() x = 1.ToString() myVar["hey"] = "ho" # An array variable can use any object as an index. BREAK LOOP WHILE myVar = arg1 OR (arg1 = arg2 AND arg2 = myVar[0]) arg2 = NEW System.DateTime() RETURN RecursivityFunction(100) END FUNCTION ASYNC FUNCTION RecursivityFunction(num) IF num > 1 THEN num = AWAIT RecursivityFunction(num – 1) TRY num.ToString() # this is a comment CATCH THROW NEW System.Exception(EXCEPTION.Message) END TRY ELSE IF NOT num = 1 THEN # another comment BREAKPOINT END IF END IF RETURN num END FUNCTION |
C’est un langage interprété, mais pouvant toutefois être compilé grâce à un convertisseur BaZic vers C#.
Plutôt que de m’attarder sur vendre du rêve là où il n’y a pas d’intérêt à le faire, je préfère vous partager la partie technique pour que vous aussi, vous puissiez vous amuser à inventer votre propre langage de programmation. 🙂
Architecture
Détaillons ici l’architecture de base du runtime et ce qui tourne derrière.
Il y a plusieurs manières de faire son propre langage de programmation. Selon la technologie sur laquelle on se base (ici, du .Net), on peut profiter de certains de ces composants pour automatiser ou optimiser certaines parties. Avec du .Net justement, on peut créer notre propre langage compilé, ce qui nécessite une excellente compréhension et maitrise de du CLR et CLI. On peut utiliser LEX et YACC pour générer un arbre syntaxique. Mais dans le cas du BaZic, j’ai voulu faire un interpréteur et un Parser fait maison. Ainsi, le runtime BaZic est composé de 5 parties :
- Lexer
Ce composant a pour but de convertir le code source textuel vers un tableau de jetons représentant tout ce qu’il y a dans le code. - Parser
Le parser va ensuite utiliser ce tableau de jetons pour détecter des suites logiques afin de générer un arbre syntaxique abstrait (on détaillera plus bas). - Optimizer
Durant cette étape, on va chercher à faire des ajustements dans l’arbre syntaxique abstrait pour optimiser en vitesse le code, ou faire tout un tas d’arrangements qui simplifient la vie à l’interpréteur. - Interpreter
Ce composant va donner vie au code source en tentant d’exécuter des tâches en fonctions des opérations et expressions qui se trouvent dans l’arbre syntaxique abstrait. - Translator & Compiler
Enfin, si on a choisit de compiler au lieu d’interpréter, on va convertir l’arbre syntaxique en C#, et utiliser le compilateur de Microsoft pour obtenir un Assembly. Rien de très intéressant dans ce dernier point qui ne soit pas déjà expliqué en 36 000 exemplaires sur internet, donc je passerais mon chemin.
Derrière le langage BaZic, il y a du C# qui tourne. C’est mon langage préféré donc il ne faut pas s’étonner. 😉 Le C# offre l’avantage de gérer la mémoire RAM de manière très transparente, ce qui nous arrange dans notre cas car c’est juste pour apprendre, s’amuser, et qu’il y a assez de points complexes à gérer pour en plus devoir gérer la RAM.
Mais l’inconvénient est que c’est beaucoup plus lent que si l’on avait directement codé en C#, car pour faire, par exemple, une simple addition, le programme exécute beaucoup plus de tâches que si c’était directement du C#.
Lexer
Comme expliqué rapidement ci-dessus, la première étape est donc le Lexer. Son but est de prendre un code source, sous forme de texte, et de le découper mot par mot afin de générer un tableau de jetons qui représente le contenu du code source.
Mais au fait, qu’est-ce qu’on entend par « jeton » ici?
Un jeton est un objet qui va contenir plusieurs informations :
- Le type de jeton : est-ce que le bout de texte détecté dans le code source est un mot clé, un nombre entier, un symbole?
- Le texte découpé : le mot clé, nombre entier ou symbole tel qu’il apparait dans le code source.
- La ligne à laquelle le texte commence.
- La colonne, dans la ligne, à laquelle le texte commence.
Les deux dernières informations seront utiles dans le Parser.
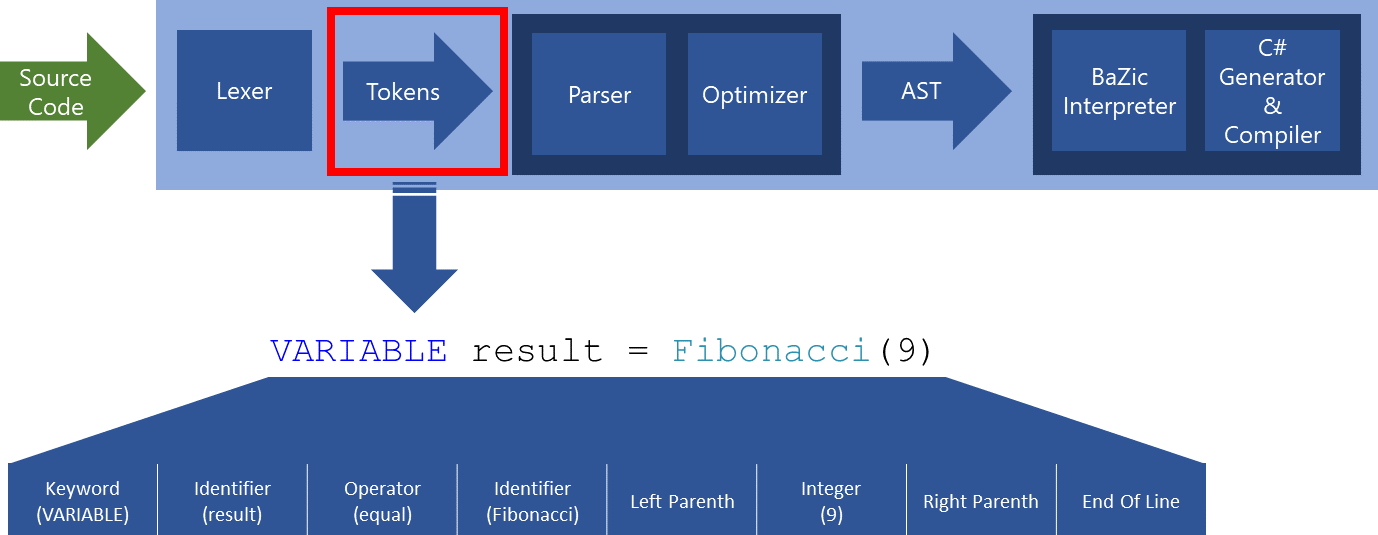
Dans l’exemple explicité dans le schéma ci-dessus, on a découpé cette ligne de code en 8 jetons :
- Mot clé : Variable
- Identifiant : « result »
- Opérateur : Symbole égale « = »
- Parenthèse gauche
- Nombre entier : « 9 »
- Parenthèse droite
- Fin de la ligne
On peut constater que l’on ne tient pas compte des espaces et tabulations car, dans le cas spécifique de ce langage de programmation, ils ne sont pas important. En revanche, on indique, via un jeton, où se trouve la fin d’une ligne de code, car dans ce langage, il y a une opération par ligne (comme en Basic, Visual Basic, Visual Basic.Net…etc).
Parser
Une fois que tout le code source a été transformé en un tableau de jetons, celui-ci est envoyé au Parser. Ce composant va analyser l’ordre des jetons dans le tableau pour y détecter des suites logiques afin de déterminer les opérations et expressions dans le code. Ces opérations et expressions détectées vont faire partir d’un ensemble que l’on appelle « arbre syntaxique abstrait ». En anglais, Abstract Syntax Tree (AST).
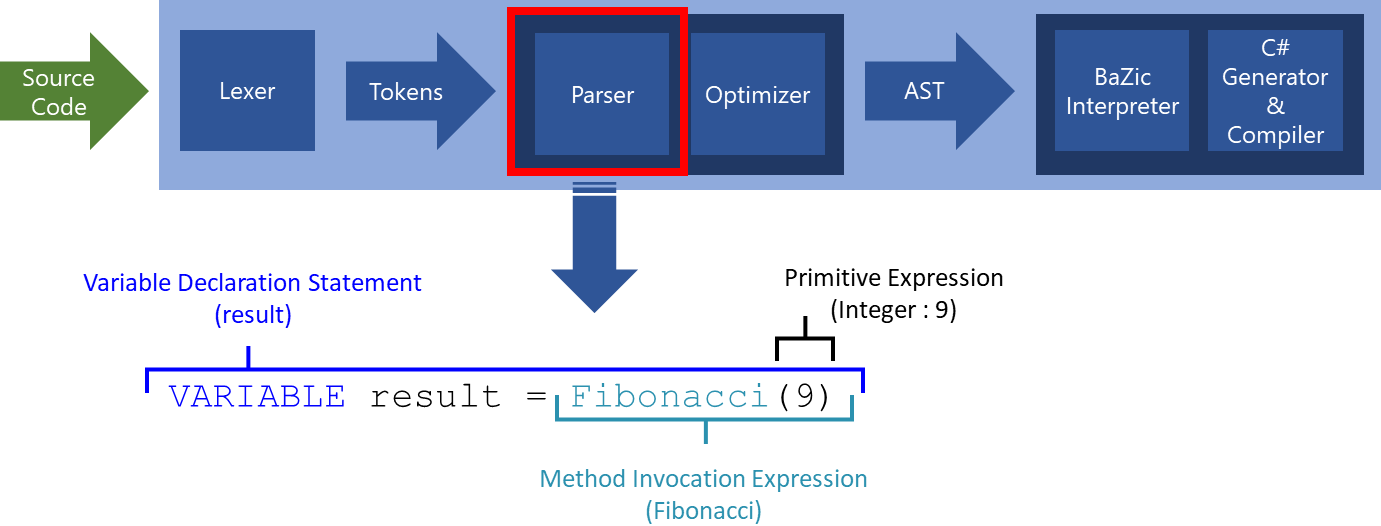
Reprenons en exemple la ligne de code précédente.
|
1 |
VARIABLE result = Fibonacci(9) |
Cette ligne représente la déclaration de la variable « result » ayant pour valeur par défaut le résultat d’un appel à la méthode Fibonacci de 9.
Dans le Parser, un ensemble d’algorithmes permettent de détecter la syntaxe (simplifiée) suivante :
|
1 |
'VARIABLE' Identifier ('=' Expression)? |
Comprenez ici, le mot clé « VARIABLE », suivi d’un Identifiant, puis facultativement suivi du symbole d’égalité (=) et d’une expression. On appelle cela une grammaire.
Ce que fait le Parser exactement peut être exprimé dans le monologue suivant :
- Est-ce que la ligne commence strictement par le mot-clé « VARIABLE »?
- Oui? Ah cool. Qu’est-ce qu’il y a ensuite? Ah ! Un identifiant.
- D’accord donc j’en déduis que cette ligne est sûrement la déclaration d’une variable ayant pour nom l’identifiant en question (dans notre exemple, « result » est l’identifiant).
- Ensuite, je peux avoir, ou pas, un symbole égal. Je vois qu’il y en a un.
- OK, donc normalement je dois avoir une expression qui suit.
- [Pour simplifier, je ne vais pas détailler ce qu’on fait pour analyser les expressions]
- Super, donc la valeur par défaut de la variable déclarée est l’expression en question.
En allant un peu plus loin, on peut rajouter la condition suivante (non-exhaustive) :
- Si la ligne commence strictement par le mot-clé « VARIABLE »
- Et que le jeton suivant N’EST PAS un identifiant, alors on a une erreur de syntaxe.
Et c’est ainsi que l’on peut utiliser les informations Lignes et Colonnes contenus dans les jetons pour informer l’utilisateur qu’il a fait une faute.
Ci-dessous, un exemple d’erreur de syntaxe affiché par le mini environnement de développement que j’ai fait pour exécuter des programmes en BaZic.

Optimizer
L’interpréteur de BaZic est globalement lent. Plusieurs choses ont été mises en places pour l’accélérer, tel que la mise en cache des propriétés et méthodes .NET résolues dynamiquement à l’exécution (Reflection), des chemins rapides et autre. Mais ça ne suffit pas.
Une autre possibilité est de modifier l’AST (Abstract Syntax Tree, arbre syntaxique abstrait) afin de l’améliorer en vitesse sans modifier son comportement.
Il n’y a pas beaucoup d’optimisation faite par ce composant. Néanmoins, il y en a une principale très importante : l’alignement des méthodes.
En BaZic, et tout comme dans beaucoup de langages, un appel à une méthode est une action couteuse en terme de performance. Dans le runtime BaZic, la raison principale est la création d’un nouveau Scope.
Un autre problème lié aux appels de méthodes est le dépassement de pile d’appels (Call Stack Overflow). Comme l’interpréteur exécute les opérations et expressions de manière récursives, une StackOverflowException arrive rapidement. L’alignement des méthodes dans l’AST peut aider à régler ce problème, car cela réduira le nombre d’appels récursifs et réduira donc la pile d’appels de l’interpréteur.
Dans le schéma ci-dessous, on a aligné la méthode « DoubleIncrement » à l’endroit où elle est appelé. Ainsi, au lieu d’appeler la méthode Foo, et dedans, d’appeler la méthode « DoubleIncrement », on appelle plus qu’une seule méthode.
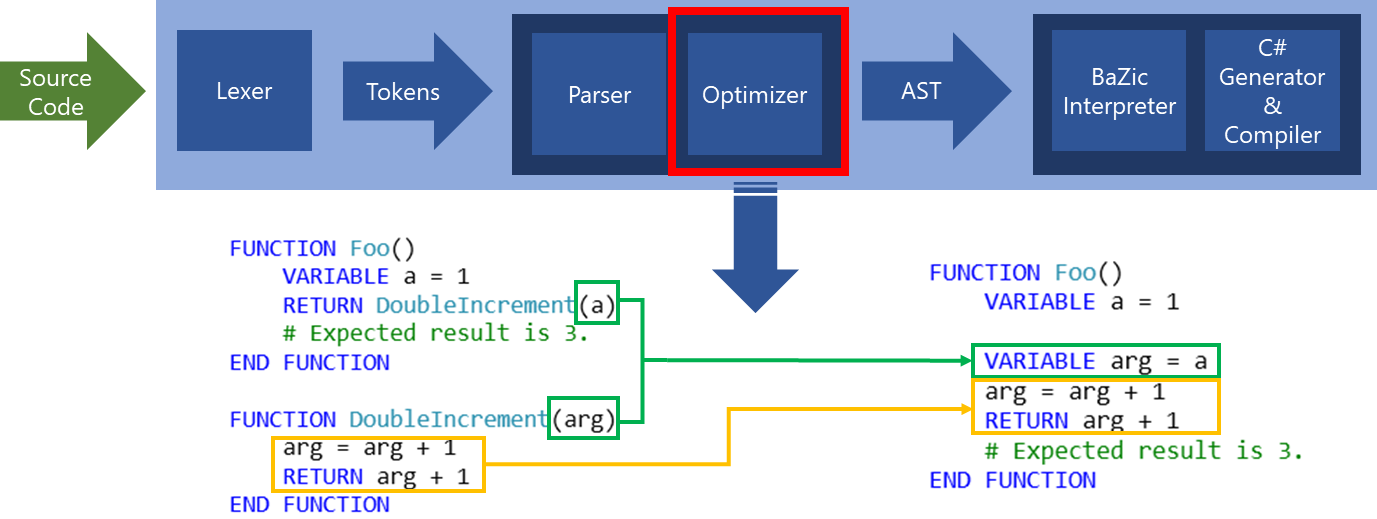
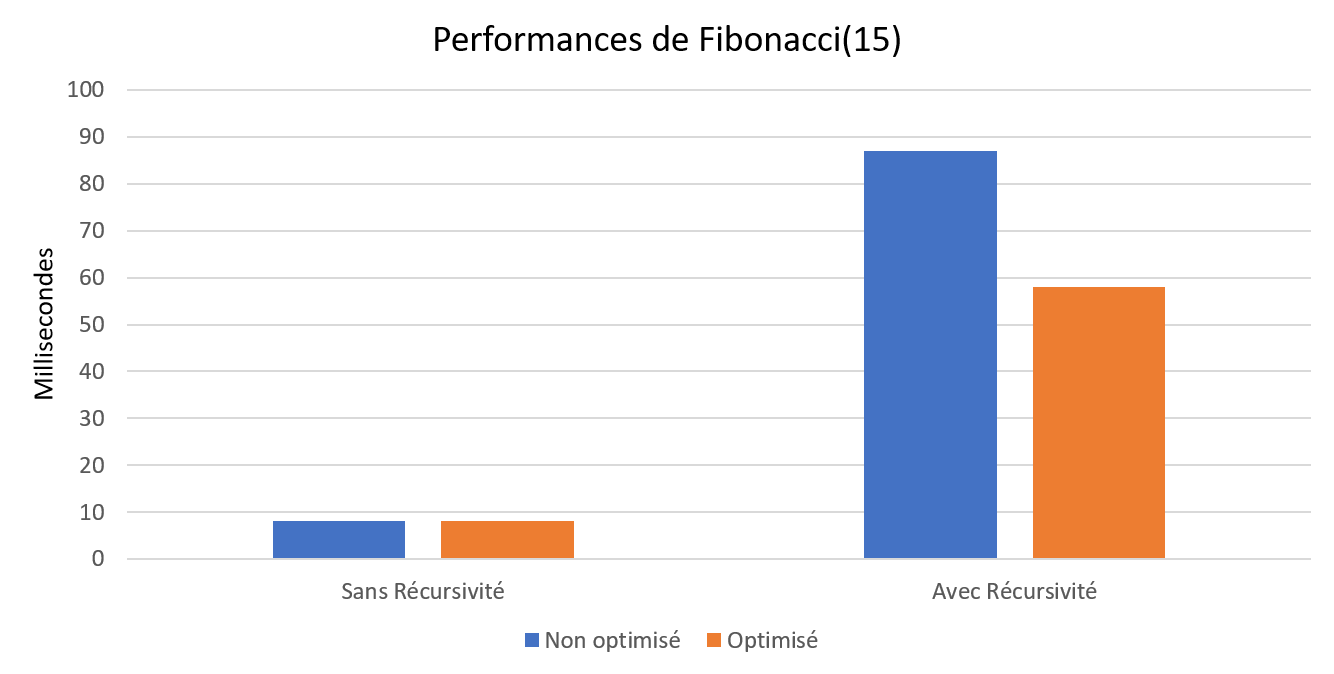
Dans le cas de la suite de Fibonacci exécutée de manière récursive (qui est une manière lente de procéder dans le cas de Fibonacci), cette optimisation permet un gain de vitesse d’environ 33%.
L’AST final est ensuite envoyé à l’interpréteur.
Interpreter
Comme évoqué brièvement plus tôt, l’interpréteur va tenter d’exécuter de manière récursif les opérations et expressions de l’AST. Ce n’est pas très complexe en soit. Il y a juste beaucoup de cas à gérer.
Variables
Très simplement, pour chaque Scope créé, un dictionnaire est instancié en mémoire, avec sa valeur et son nom, tout simplement.
Librairies
Dans de nombreux cas, on aimerait pouvoir utiliser une API .Net dans un code BaZic. Cela sous-entend qu’il faut référencer un ou plusieurs Assemblies. Pour des soucis de gestion de la mémoire RAM, de blocage de fichiers utilisés sur le disque dur et de sécurité, tout l’interpréteur et ses Assemblies nécessaires au bon fonctionnement du programme BaZic sont exécutés dans une Sandbox (à base d’Appdomain). Ainsi, l’interpréteur se charge, s’exécute puis se décharge à la fin.
Reflection
Les valeurs que l’on peut utiliser en BaZic dans des variables, méthodes ou propriétés sont des objets .Net (System.String, System.Int32…etc). Les propriétés et méthodes sont résolues dynamiquement au moment de l’interprétation (pas du parsing). Mais la Reflection en .Net a un coût non négligeable. Ainsi, un helper a été créé afin de mettre en cache les endpoints vers les propriétés et méthodes que l’on découvre et potentiellement réutilisons dans notre programme BaZic afin d’y accéder plus rapidement.
Translator & Compiler
Dans cette partie, je vais avoir honte. 🙂
Il est possible de générer un Assembly .NET à partir d’un code source BaZic. Mais à l’heure où j’écris cet article, ce n’est pas de la compilation directe. Le runtime génère un code C# à partir de l’AST, puis utilise Roslyn pour générer un Assembly.
Le langage BaZic est un langage procédural. Afin que le C# généré conserve exactement le même comportement qu’un code BaZic interprété, un helper (qui est très sale, je l’avoue) est là pour faire en sorte que le programme compilé ai le même résultat. A cause de ce helper, les performances du programme compilé sont mauvaises. La vitesse est similaire à celle de l’interpréteur (haha, j’ai honte).
Une amélioration et évolution possible ici est de créer mon propre compilateur .Net pour BaZic plutôt que de passer par une conversion en C#. Si c’est bien fait, les performances devraient être drastiquement meilleures.
Découvrir et essayer sur GitHub
Envie d’essayer d’exécuter du BaZic? Envie de découvrir ce qu’il y a sous le capot et comment ça fonctionne niveau code? Envie de le réutiliser dans un projet?
Le runtime BaZic est OpenSource. Profitez-en. Cliquez sur le logo GitHub pour y accéder 😀
![]()
Un package NuGet est également disponible.
N’hésitez pas à poser vos questions dans les commentaires. 🙂
Au plaisir 😉

